

98%??? What is going on here?
Normally it's in the 20-30% block range. So I go scrolling down the admin page
a little and there's this spike around 6AM. A big spike. A really big spike.

This has a feel of some nefarious
malware going on. Did my parents join a botnet?

Looking further in the GUI, there
were two hosts that caused the jump in lookups.

Both of the top ones are Domain Controllers. At this site, DHCP hands out only the Pi-Hole server and the Pi-Hole is configured to query the DCs for local DNS and Active Directory. They in turn are configured to use the Pi-Hole as their upstream instead of the roots as is the default.
Trying to dig into the logs via the GUI was not going anywhere. There was just too much data and it kept timing out. I did not do any command line parsing of the logs here; thought I'd start with the basics since this was a recent occurrence. The first thing I did was to check all the Windows systems with things like MBAM and Crowdstrike tools, and I looked at the DCs way more closely. Nothing was found. Next was to make sure everything was using the Pi-Hole for DNS. All the Windows devices were, except the DCs; they are set to best practice which is to point to the other than themselves. Note this was the IP of itself, not loopback (127.0.0.1). When I reverted this change, I used loopback.
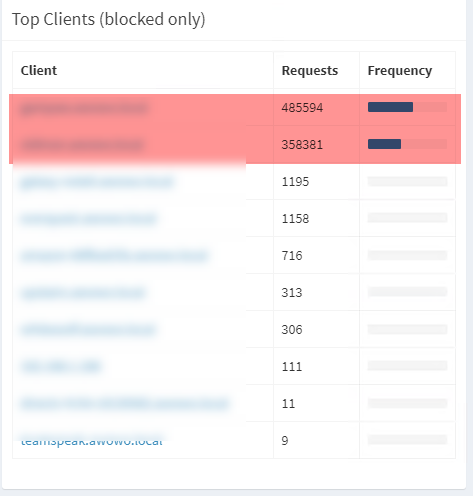
Back on the Pi-Hole, I found several
names that concerned me, places their environment should not be going to, so I
started adding those to the blacklist in Pi-Hole. Another day, new hosts in CN
TLD.

The two SH.CN hosts became #1 and #2
after I blocked the two highlighted ones above.
The light above my head went off. I
only looked at the Windows hosts, not the rest. So I go see what DNS they point
to. ESX was using the DCs so I changed it to the Pi-Hole. My backup Linux
server was using the Pi-Hole, and both DCs.
Linux does not have the concept of
primary DNS and Secondary DNS, just DNS Server 1, 2, etc. At this point I
performed a cardinal sin in tracking problems down – I changed multiple things.
Ugh. I changed this Linux box to use Pi-Hole only. Secondly, I changed the DCs
to point to Pi-Hole as primary and the other DC as secondary. I also turned on
DNS logging on the DCs. The next day lookups dropped exponentially but were
still high around 6AM, with around 6000 lookups instead of the nearly billion.
All PTR records. That's strange. The DNS logs in the DCs only showed normal
traffic for the Active Directory domain with a few Microsoft domains being
forwarded to the Pi-Hole.
kevin@backupserver:~$ cat /etc/crontab
# /etc/crontab: system-wide crontab
# Unlike any other crontab you don't have to run the `crontab'
# command to install the new version when you edit this file
# and files in /etc/cron.d. These files also have username fields,
# that none of the other crontabs do.
SHELL=/bin/sh
PATH=/usr/local/sbin:/usr/local/bin:/sbin:/bin:/usr/sbin:/usr/bin
# m h dom mon dow user command
17 * * * * root cd / && run-parts --report /etc/cron.hourly
25 6 * * * root test -x /usr/sbin/anacron || ( cd / && run-parts --report /etc/cron.daily )
47 6 * * 7 root test -x /usr/sbin/anacron || ( cd / && run-parts --report /etc/cron.weekly )
52 6 1 * * root test -x /usr/sbin/anacron || ( cd / && run-parts --report /etc/cron.monthly )
#
I remove logwatch script from cron.daily and the next day, no spike in lookups. I have a sigh of relief. It’s not compromised, just misconfigured. Looking at the logwatch email, the fail2ban section was most of it. For some reason my parents’ ISP gets scanned a lot more than mine. Partly due to me using GeoIP via PFBlockerNG in PFSense and them using a commodity router. This backup server does have SSH enabled, certs-only, no logins. I use fail2ban to block brute force SSH attempts. It adds the IP to the firewall blocking them after X attempts by watching various log files, and it has a module for logwatch.
I'm not finding anything in its files, so parsing fail2ban wiki I find this article around DNS lookups. Sure enough, /etc/fail2ban/jail.local, use_dns is set to Yes. I change it to No and the daily lookups drop to around 1000. I checked another system and it was set to warn. I changed it to No as well. I don’t care what DNS reports back from these IPs doing the scanning.
All happy now and back where expected.

There is still a small spike but
much more tolerable.

So what happened? While Logwatch was the
root cause IMO, DNS misconfiguration was what happened. Fail2ban shows
thousands upon thousands of SSH login attempts. Someone smarter in DNS than me would have to confirm or deny, but my theory is all the
DNS servers did multiple lookups per record and none liked the NXDOMAIN response. My server looked it up against Pi-Hole.
It didn’t like the response, so looked up against DC A. DC A in turn looked up
against DC B, which went upstream to the Pi-Hole. It didn’t like the response
so it went to its second server, itself. DC A in turn went upstream to the Pi-Hole.
My server didn’t like the response so I went to DC B, which in turn went to its
primary, DC A, which went upstream. Then DC B went
upstream. Finally, my server stopped once it exhausted all its DNS servers. I need to draw this out!
Regarding my concern around the CN TLD, many of the IPs I researched, those hosts were the authoritative DNS for them. This partially explains why they were so high in the query lists.
-Kevin

{kind=link}